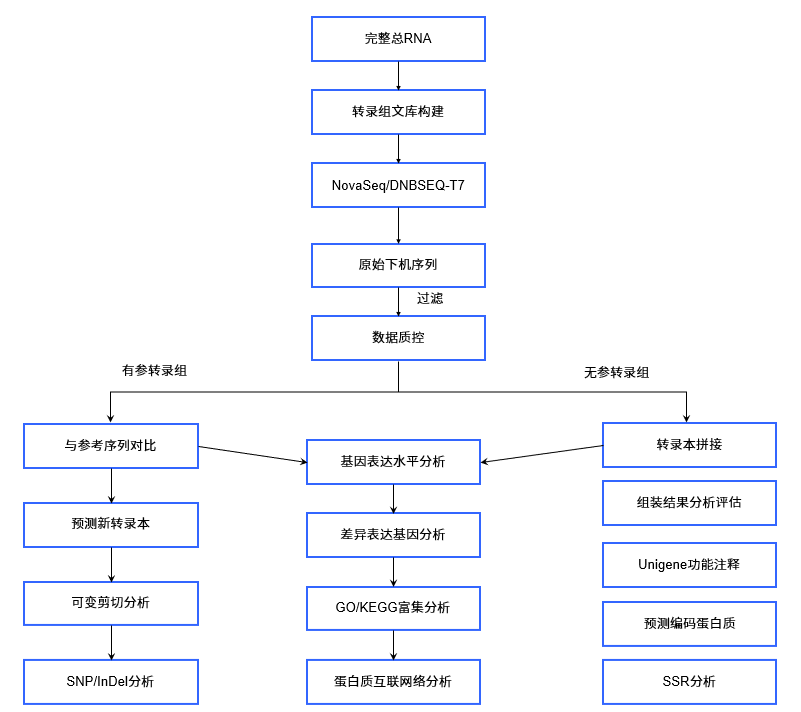
真核mRNA测序分析的研究对象为特定细胞在某一功能状态下所能转录出来的所有mRNA的总和。转录组研究是基因功能及结构研究的基础和出发点,通过新一代高通量测序,能够快速地获得某一物种特定组织或器官在某一状态下的几乎所有转录本序列信息。
高通量实验平台
拥有多台自动化提取,自动化建库平台,高质量完成实验任务
建库质量
采用官方指定、主流期刊认可建库试剂,建库成功率>98%
质控标准
从样品入库到数据交付各环节严格质控
医学特色分析
新增转录本分析、肿瘤微环境、新生抗原、融合基因等多项医学特色分析
医学分析团队
专业的医学转录组生物信息分析工程师团队,提供专业服务
个性化分析
拥有转录组个性化分析库满足客户需求,项目经验10000+,分析工具100+
高通量测序平台
NovaSeq 6000、DNBSEQ-T7测序平台
在临床前模型和 I 期试验中鉴定和评估一种降脂小化合物
Identifification and evaluation of a lipid-lowering small compound in preclinical models and in a Phase I trial
期刊:Cell Metabolism 发表时间:2022 影响因子:27.287 合作单位:中国科学院上海药物研究所 合作方式:提供服务
心血管疾病是目前全球引起疾病死亡重大原因之一,而高胆固醇引起的血脂异常是导致心血管疾病死亡的重大风险之一。他汀类药物是高血脂的一线治疗药物,但是15%的患者存在他汀不耐受或者他汀降脂效果不佳等临床缺陷。因此,开发有效安全的高血脂治疗药物具有重要的研究意义。
利用HepG2细胞系和高脂饮食诱导的高脂血症仓鼠和自发性高脂血症恒河猴分别进行体外和体内实验,发现DC371739在体内外均表现出强大的降脂作用。

图1 DC371739促进HepG2细胞的DiI-LDL摄取,并改善HFD喂养的仓鼠、自发性高脂血症恒河猴和高胆固醇血症个体的高脂血症
DC371739通过干扰HNF-1α与其顺式元件的结合,破坏其与DNA的结合,从而阻碍PCSK9和ANGPTL3这两个关键基因的转录。

图2 C371739通过直接靶向HNF-1α抑制PCSK9和ANGPTL3启动子活性
DC371739与阿托伐他汀钙联合用药,可进一步降低高血脂大鼠的TC、TG和LDL-C水平。

图3 DC371739和阿托伐他汀可同时增强血脂清除率
DC371739通过与HNF-1α结合抑制其转录功能,降低PCSK9和ANGPTL3的转录水平,下调了PCSK9蛋白和ANGPTL3蛋白表达,进而增加了LDLR蛋白表达和LPL活性,促进循环中LDL-C和TG的清除,从而发挥降脂作用。

图4 DC371739通过靶向HNF-1α调控PCSK9和ANGPTL3的转录
研究人员发现高血脂治疗潜在新靶标HNF-1α,并揭示了降脂候选药物DC371739独特的作用新机制,发现了其临床疗效监控生物标志物PCSK9和ANGPTL3,为高血脂症个性化临床研究奠定基础。另外,研究人员根据其独特的降脂作用机制提出DC371739与阿托伐他汀钙联合用药方案,为他汀不耐受或者他汀治疗效果不佳的患者提供了治疗的潜在新策略。
Wang J, Zhao J, Yan C, et al. Identification and evaluation of a lipid-lowering small compound in preclinical models and in a Phase I trial[J]. Cell Metabolism. 2022 May;34(5):667-680.e6. DOI: 10.1016/j.cmet.2022.03.006. PMID: 35427476.